Technical Report
OmniScript
Towards Audio-Visual Script Generation for Long-Form Cinematic Video
ARC Lab, Tencent · *Equal Contribution
Towards Audio-Visual Script Generation for Long-Form Cinematic Video
ARC Lab, Tencent · *Equal Contribution
TL;DR — An 8B omni-modal model that converts long cinematic videos into structured, temporally-grounded scripts.
Current multimodal large language models (MLLMs) have demonstrated remarkable capabilities in short-form video understanding, yet translating long-form cinematic videos into detailed, temporally grounded scripts remains a significant challenge. This paper introduces the novel Video-to-Script (V2S) task, aiming to generate hierarchical, scene-by-scene scripts encompassing character actions, dialogues, expressions, and audio cues. To facilitate this, we construct a first-of-its-kind human-annotated benchmark and propose a temporally-aware hierarchical evaluation framework. Furthermore, we present OmniScript, an 8B-parameter omni-modal (audio-visual) language model tailored for long-form narrative comprehension. OmniScript is trained via a progressive pipeline that leverages chain-of-thought supervised fine-tuning for plot and character reasoning, followed by reinforcement learning using temporally segmented rewards.
Extensive experiments demonstrate that despite its parameter efficiency, OmniScript significantly outperforms larger open-source models and achieves performance comparable to state-of-the-art proprietary models, including Gemini 3-Pro, in both temporal localization and multi-field semantic accuracy.
Generating hierarchical, temporally-grounded scripts from long-form cinematic videos.
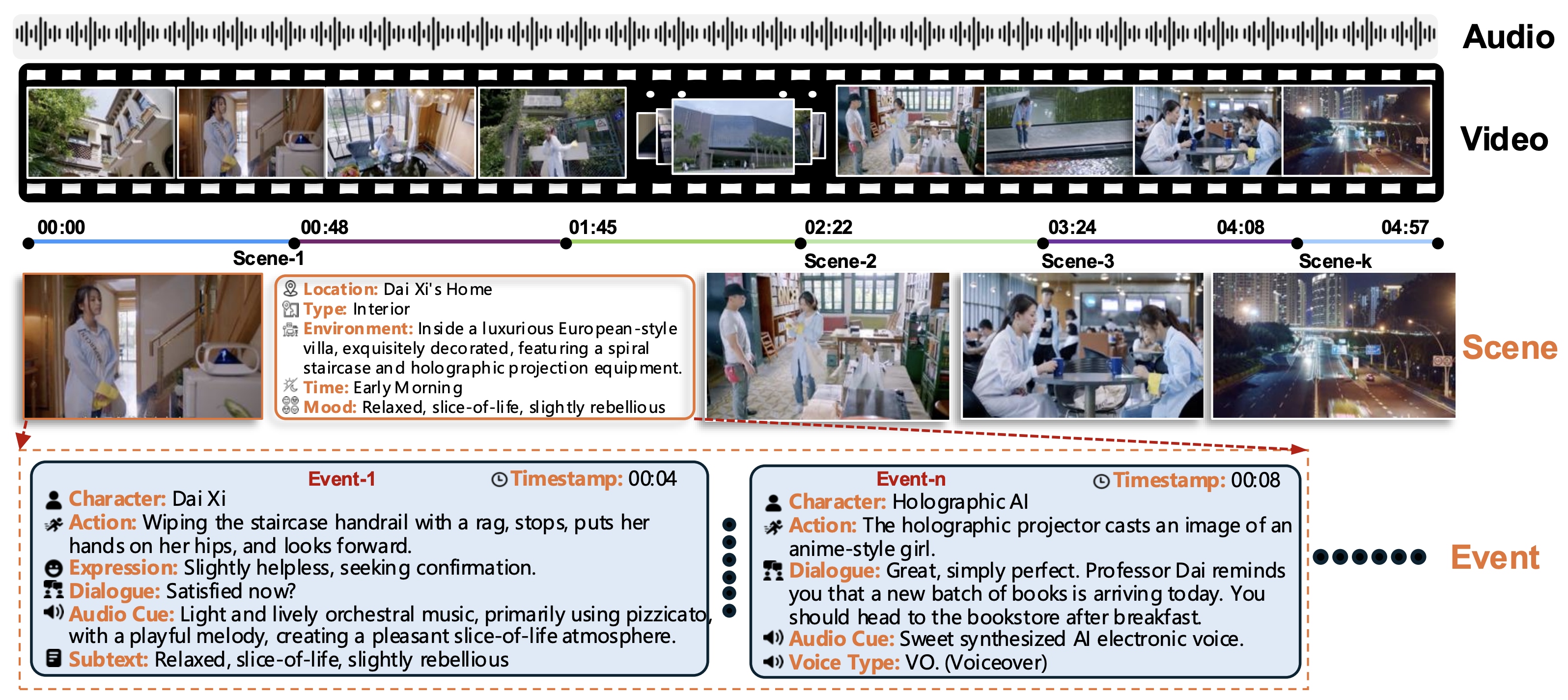
Figure 1: Overview of our Video-to-Script (V2S) framework. Given a long-form cinematic video, the pipeline performs temporally grounded scene-event parsing and generates a structured script with multimodal fields (dialogue, action, expression, and audio cues).
Given an untrimmed cinematic video containing complex narrative transitions, recurring characters, and multimodal cues, the model produces a structured output organized into three hierarchical levels:
Global attributes including title, total duration, and a comprehensive character list for the entire video.
A sequence of scenes, each with location, environment description, time attribute (day/night), and mood.
Ordered events within each scene, with timestamps, character identity, dialogue, action, expression, and audio cues.
OmniScript: an omni-modal (audio + visual + language) model built on Qwen3-VL with AV-DeepStack injection.
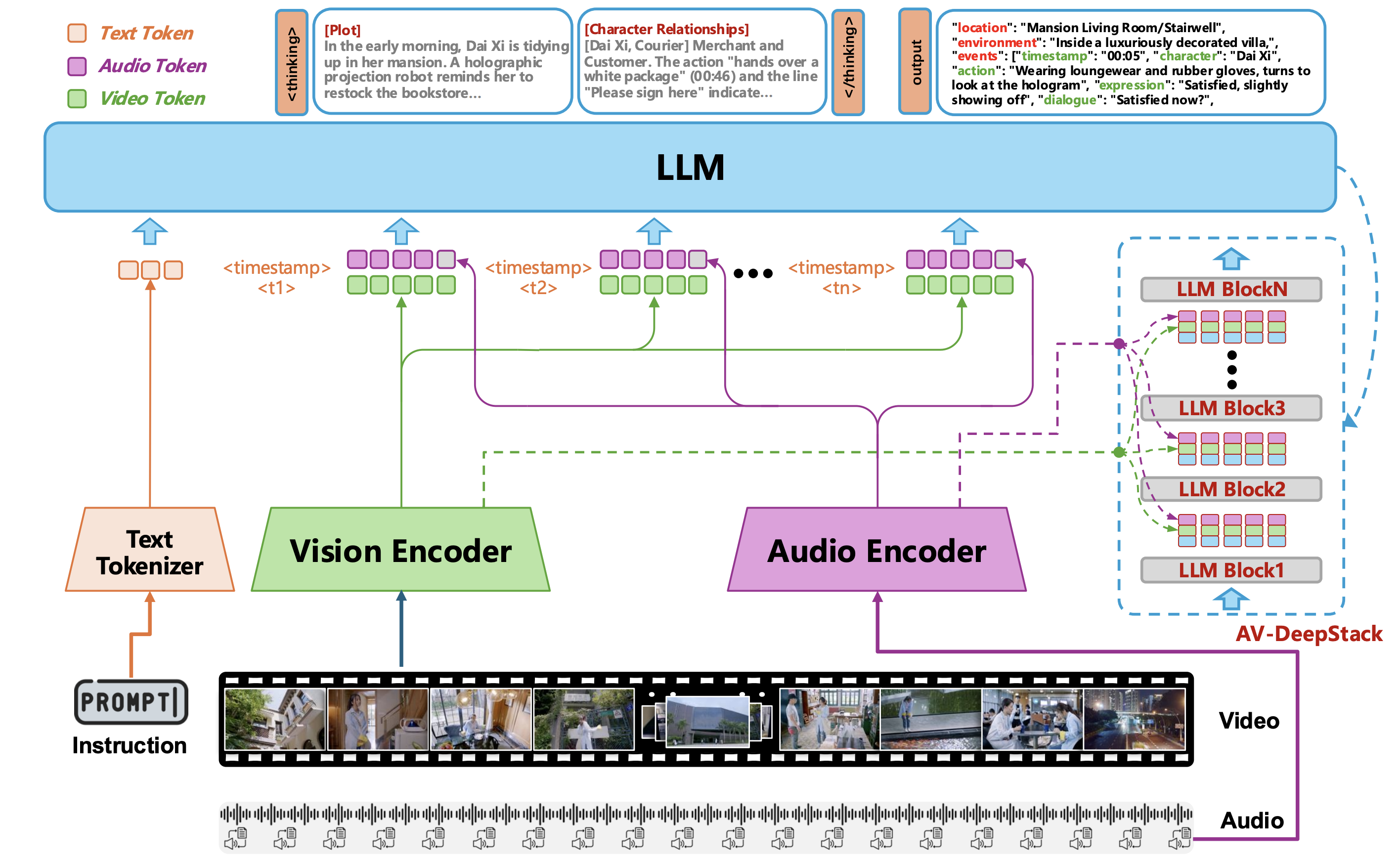
Figure 3: Overview of the proposed architecture. Instruction, video, and audio are encoded into multimodal tokens and fused in the LLM via AV-DeepStack across multiple layers. The model first performs multimodal plot and character-relationship reasoning and then generates structured script outputs.
Strict timestamp-level alignment between visual frames and Whisper-encoded audio features, preserving cross-modal synchrony for dialogues, narration, environmental sounds, and BGM.
Audio tokens are paired with visual tokens and jointly injected across stacked transformer layers via residual multimodal adapters, enabling repeated cross-modal interaction during deep semantic inference.
Chain-of-Thought paradigm: the model first generates a plot summary and character-relationship state, then uses this as a scaffold for coarse-to-fine structured script generation.
A four-stage training recipe followed by reinforcement learning refinement.
Train audio projector on 1M bilingual ASR samples. Freeze ViT, Whisper, LLM. Random frame masking.
Full fine-tuning on 2.4M videos. Multi-task: ASR, captioning, summarization, temporal grounding.
45K curated videos. Chain-of-Thought traces with plot reasoning and character relationship mapping.
Temporally segmented rewards. Event-level one-to-one matching for fine-grained error penalization.
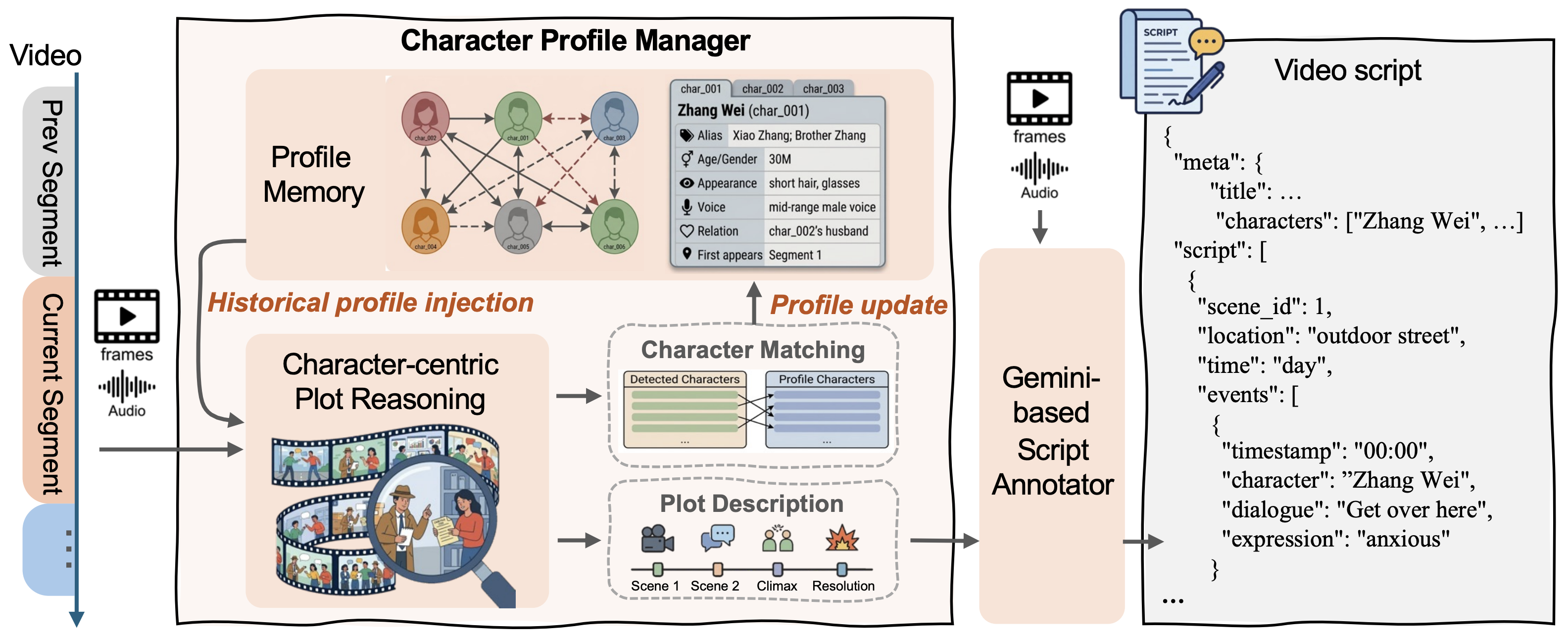
Figure 2: Overview of the memory-augmented progressive annotation pipeline. The character profile manager injects historical profiles to guide plot reasoning and dynamically updates character memory. The generated plot description and raw audio-visuals are then fed into a Gemini-based annotator to produce a fine-grained video script.
A Character Profile Manager (CPM) maintains cross-segment character memory, enabling consistent identity resolution and coherent plot descriptions across long videos. Uses lazy naming strategy for entity resolution.
CoT trajectories driven by plot and character dynamics. A strong LLM retroactively distills intermediate thinking from generated scripts, creating structured Video → Thinking → Script training data.
A meticulously curated benchmark with hierarchical evaluation metrics.
OmniScript (8B) outperforms much larger open-source models and rivals proprietary systems.
| Model | Params | Omni | Char. | Dia. | Act. | Exp. | Aud. | Overall | tIoU@0.1 |
|---|---|---|---|---|---|---|---|---|---|
| Proprietary Models | |||||||||
| Gemini-3-flash | – | ✓ | 28.8 | 50.3 | 28.2 | 25.5 | 11.2 | 28.8 | 44.3 |
| Gemini-3-pro | – | ✓ | 39.8 | 68.8 | 37.4 | 35.4 | 13.3 | 38.9 | 64.4 |
| Gemini-2.5-flash | – | ✓ | 40.1 | 75.5 | 42.8 | 36.5 | 22.8 | 43.6 | 74.3 |
| Gemini-2.5-pro | – | ✓ | 41.7 | 75.0 | 41.9 | 39.0 | 17.0 | 42.9 | 73.4 |
| Seed-1.8 | – | × | 40.9 | 54.4 | 35.1 | 29.6 | 12.4 | 34.5 | 50.7 |
| Seed-2.0-pro | – | × | 47.4 | 68.1 | 42.9 | 35.7 | 10.3 | 40.9 | 67.1 |
| Open-Source Models | |||||||||
| Qwen3VL | 8B | × | 30.4 | 49.6 | 26.9 | 25.3 | 6.6 | 27.7 | 47.6 |
| Qwen3-Omni | 30/3B | ✓ | 4.9 | 3.4 | 5.5 | 7.3 | 4.4 | 5.1 | 12.8 |
| Qwen3VL | 32B | × | 37.1 | 57.1 | 31.3 | 28.7 | 7.2 | 32.3 | 52.5 |
| Qwen3VL | 235/22B | × | 38.1 | 58.6 | 33.0 | 29.1 | 6.0 | 33.0 | 62.0 |
| Ours | |||||||||
| OmniScript | 8B | ✓ | 39.2 | 72.2 | 33.7 | 31.9 | 11.6 | 37.7 | 69.3 |
| Model | Params | Omni | Loc. | Type | Env. | Time | Mood | Overall | tIoU@0.1 |
|---|---|---|---|---|---|---|---|---|---|
| Proprietary Models | |||||||||
| Gemini-3-flash | – | ✓ | 54.6 | 59.8 | 42.7 | 54.9 | 50.4 | 52.5 | 70.3 |
| Gemini-3-pro | – | ✓ | 58.8 | 63.1 | 46.9 | 61.6 | 54.8 | 57.0 | 75.3 |
| Seed-2.0-pro | – | × | 57.7 | 62.2 | 49.2 | 62.7 | 54.3 | 57.2 | 75.5 |
| Open-Source Models | |||||||||
| Qwen3VL | 8B | × | 41.3 | 49.7 | 31.8 | 39.8 | 41.7 | 40.9 | 60.6 |
| Qwen3VL | 32B | × | 50.4 | 58.7 | 42.7 | 55.4 | 47.9 | 51.0 | 71.1 |
| Qwen3VL | 235/22B | × | 52.6 | 60.2 | 45.4 | 57.9 | 50.9 | 53.4 | 72.8 |
| Ours | |||||||||
| OmniScript | 8B | ✓ | 54.0 | 58.4 | 41.9 | 58.1 | 49.5 | 52.4 | 74.6 |
| Model | CoT | Reward | Char. | Dia. | Act. | Exp. | Aud. | Overall | tIoU@0.1 |
|---|---|---|---|---|---|---|---|---|---|
| SFT | × | – | 35.6 | 68.2 | 30.5 | 31.2 | 11.1 | 35.3 | 66.6 |
| SFT | ✓ | – | 37.8 | 71.0 | 33.5 | 31.2 | 11.5 | 37.0 | 68.9 |
| SFT+RL | ✓ | Global | 39.2 | 69.0 | 32.4 | 31.8 | 12.3 | 37.0 | 68.7 |
| SFT+RL | ✓ | Segmented | 39.2 | 72.2 | 33.7 | 31.9 | 11.6 | 37.7 | 69.3 |
Vision-only models rely heavily on burned-in subtitles for dialogue recognition. Removing subtitles reveals whether a model truly understands speech.
| Model | Subtitle | Char. | Dia. | Act. | Exp. | Aud. | Overall | tIoU@0.1 |
|---|---|---|---|---|---|---|---|---|
| Qwen3VL-235B | ✓ | 38.1 | 58.6 | 33.0 | 29.1 | 6.0 | 33.0 | 62.0 |
| Qwen3VL-235B | × | 26.2 | 7.7 | 29.8 | 23.5 | 6.0 | 18.6 | 45.1 |
| Gemini-3-Pro | ✓ | 39.8 | 68.8 | 37.4 | 35.4 | 13.3 | 38.9 | 64.4 |
| Gemini-3-Pro | × | 40.4 | 60.9 | 34.7 | 33.6 | 13.2 | 36.6 | 60.3 |
| OmniScript (Ours) | ✓ | 39.2 | 72.2 | 33.7 | 31.9 | 11.6 | 37.7 | 69.3 |
| OmniScript (Ours) | × | 34.1 | 63.8 | 31.8 | 30.6 | 11.7 | 34.4 | 67.0 |
Extending OmniScript from short clips to full-length cinematic videos (10–45 minutes).
To scale OmniScript from short clips to long videos, we investigate two complementary strategies that trade off between end-to-end global reasoning and modular controllability.
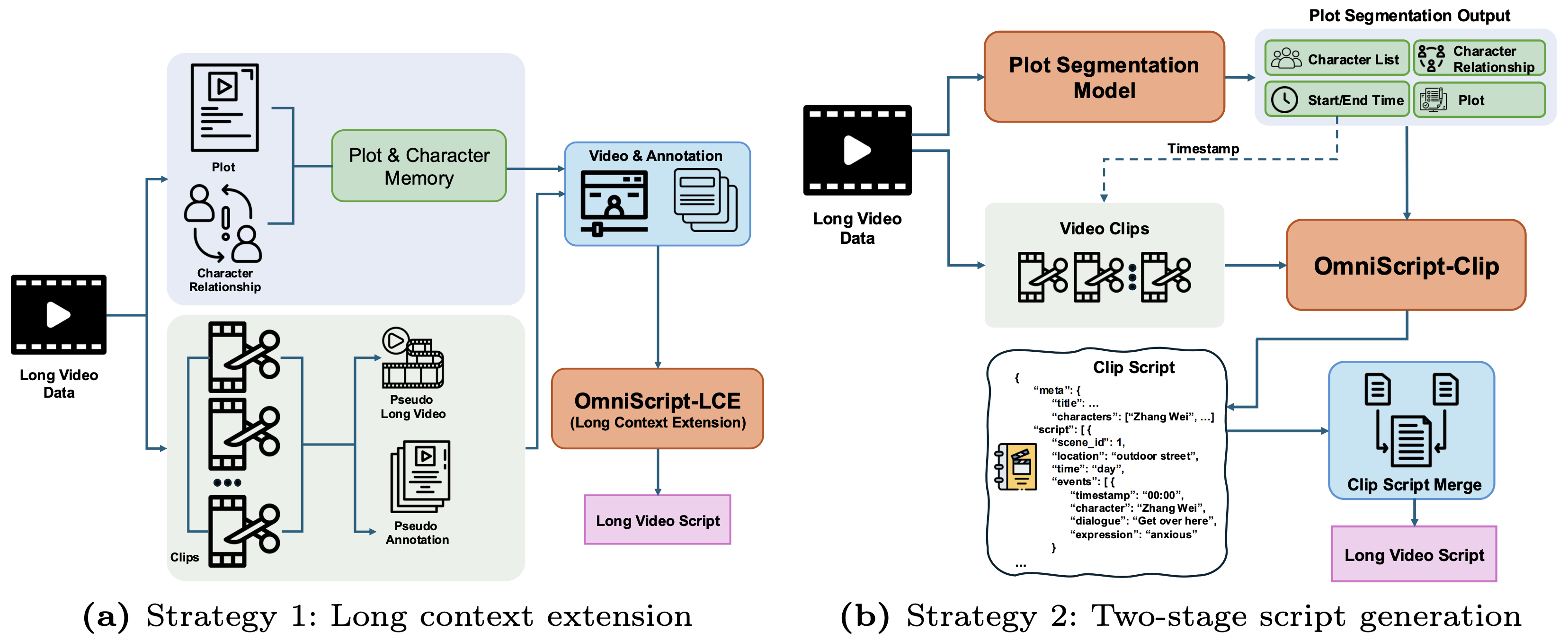
Comparison of two strategies for extending OmniScript to long videos. Left (Strategy 1): Direct long-context extension via pseudo long-video composition. Right (Strategy 2): Two-stage pipeline with plot segmentation followed by clip-level script generation and merging.
Directly scales the input context window and trains with long-video supervision. Uses cross-video composition to create pseudo long videos by concatenating thematically coherent short clips. Includes memory-refine labels for correcting historical inconsistencies. Single-stage pipeline with stronger long-range reasoning requirements.
Decomposes long-video generation into planning and writing. Stage 1: a plot-segmentation model predicts segment timestamps, plots, characters, and relations. Stage 2: each segment is processed independently by OmniScript, conditioned on structural prompts. A lightweight post-processing module merges segment scripts with temporal consistency enforcement.
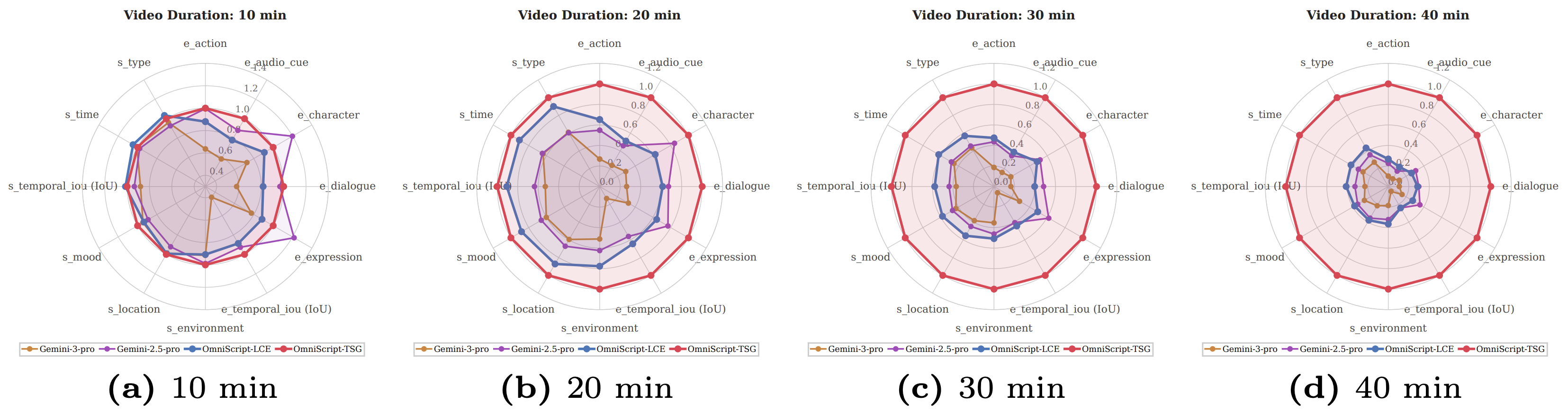
Performance comparison across video durations (10, 20, 30, 40 min) on multiple metric dimensions including event-level (action, dialogue, character, expression, audio cue, tIoU) and scene-level (location, environment, mood, time, type, tIoU) metrics.
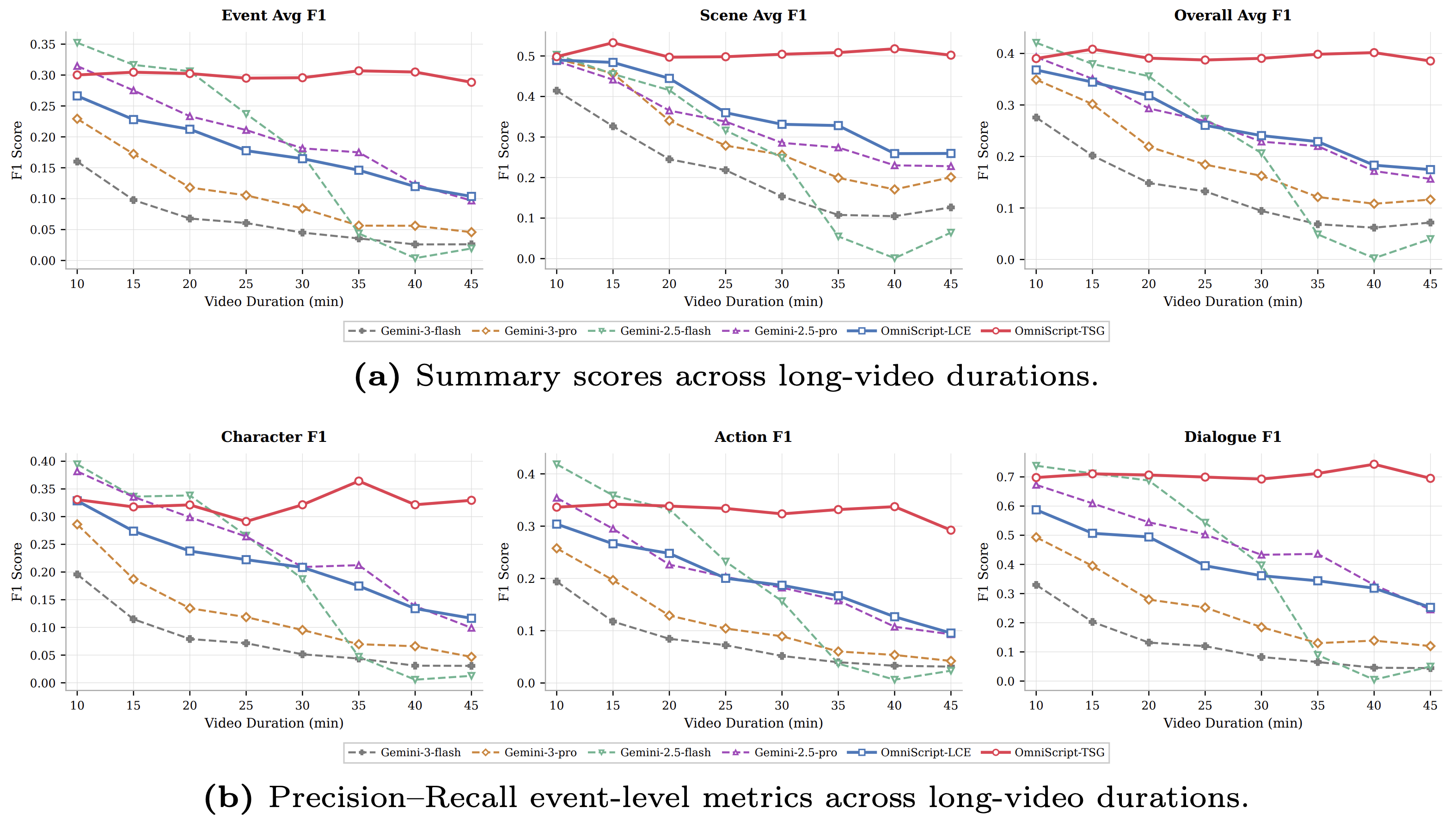
(a) Event-level, scene-level, and overall F1 scores across durations from 10 to 45 minutes. (b) Event-level fine-grained F1 scores on character, action, and dialogue. OmniScript-TSG (red) exhibits the strongest long-horizon robustness.
Explore OmniScript's structured script generation results on real cinematic videos.
If you find our work useful, please consider citing our paper.
@inproceedings{omniscript2026, title = {OmniScript: Towards Audio-Visual Script Generation for Long-Form Cinematic Video}, author = {Pu, Junfu and Chen, Yuxin and Wang, Teng and Shan, Ying}, journal = {arXiv preprint}, year = {2026} }